
 カワセミ@金融ブロガー
カワセミ@金融ブロガーこんにちは。カワセミ@金融ブロガーです
機械学習の分野では、多様な手法やアプローチが存在しますが、その根幹をなす基本的な枠組みとして「教師あり学習」と「教師なし学習」が挙げられます。
この両者の違いはシンプルに言えば、入力データに「正解ラベル」が付与されているかどうかにあります。
正解ラベルとは、例えば「この取引は不正」「この顧客は30代男性」といった、データに対して事前に与えられた答えのことです。この有無によって、モデルの学習プロセスや活用の方向性が大きく変わってきます。
教師あり学習は、既知の答えを含むデータセットを使ってアルゴリズムを訓練し、未知のデータに対して正確な予測や分類を行うことを目的としています。ビジネスシーンでは、売上予測や需要予測、顧客の購買行動分析などで広く活用されています。
過去の販売実績を学習させることで「次の四半期にどの製品が売れるのか」を推定できるほか、顧客データをもとに「このユーザーは解約する可能性が高い」と予測することも可能です。これは回帰分析や分類といったアルゴリズムを通じて実現され、マーケティング戦略や経営判断の高度化に直接つながります。
教師なし学習は、正解ラベルのないデータを用いて、潜在的なパターンや構造を発見するアプローチです。代表的な例がクラスタリングで、顧客を購買傾向や属性に基づいてグループ分けし、ターゲティング戦略に活かすことができます。
主成分分析(PCA)のようにデータの次元を圧縮して本質的な特徴を抽出する手法も、複雑なデータを理解しやすくするために重要です。顧客セグメントの発見や新しい市場ニーズの探索といったビジネス上の洞察を得ることが可能になります。
本記事では、機械学習の基礎的な考え方としてこの二つの学習方法を整理し、代表的なアルゴリズムや活用事例を取り上げながら、それぞれの特徴を直感的に理解できるように解説していきます。
やや専門的な用語も登場しますが、実務にどう応用できるのかをイメージできるように噛み砕いて説明しますので、データ分析やAI活用を検討しているビジネスパーソンの方にも役立つ内容となるはずです。
・機械学習の最も基本的な2つの学習を見ていきます
教師あり学習とは?
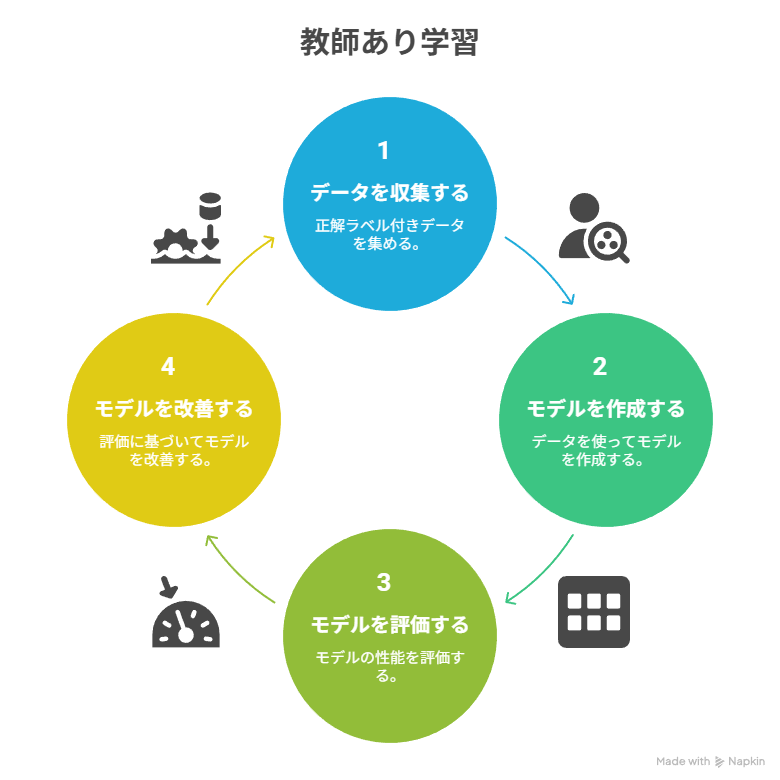
教師あり学習とは、機械学習の代表的な手法の一つで、あらかじめ正解が分かっているデータ(正解ラベル)を使ってモデルを訓練する方法です。
過去の株価データとそのときの企業の業績情報を入力データとし、翌日の株価の上昇・下降を「正解ラベル」として学習させると、将来の株価動向を予測するモデルを作ることができます。
ここで重要なのは、入力と出力がペアになっている点です。入力だけでなく「正しい答え」を与えることで、モデルは誤差を少しずつ修正しながら精度を高めていきます。
教師あり学習の代表的な手法には、線形回帰やロジスティック回帰、サポートベクターマシン、決定木、そしてディープラーニングがあります。
金融分野では、融資審査における信用スコアの算出、不正取引検知、株価予測、顧客離反の予測など、幅広い場面で活用されています。例えば、過去の顧客属性と返済履歴を学習させれば、新規顧客が融資を返済できる可能性を予測できるのです。
教師あり学習のメリットは、予測や分類の精度が高く、結果を解釈しやすいことです。大量の正解データが必要になるという課題があります。特に金融業界では、データの収集やラベル付けにコストがかかるため、その点を考慮した導入が求められます。
分類と回帰:2種類の予測タスク
分類と回帰は、教師あり学習における2大タスクとして広く利用されています。
分類は、与えられたデータがどのグループに属するかを判定する問題です。
金融分野では「顧客が融資を返済できるか否か」「取引が不正か正常か」といった二値分類が典型例です。多値分類では「顧客をリスクレベル別に区分する」など複数のクラスに分ける応用もあります。分類タスクでは、正答率や再現率といった評価指標が使われ、どれだけ正確にクラスを見分けられるかが重視されます。
回帰は数値そのものを予測する問題です。
金融では「将来の株価」「企業の売上」「為替レート」など連続的に変化する値を対象とします。回帰モデルは、入力データから数値を予測する能力を高めるために、平均二乗誤差や平均絶対誤差といった指標を使って学習します。特に数値予測では、ほんの少しの誤差が大きな損益につながるため、精度の高いモデルが求められます。
分類と回帰は一見異なるように見えますが、いずれも「入力から出力を推定する」という点で共通しています。データの性質に応じて、カテゴリ予測が必要か、数値予測が必要かを見極めることが、教師あり学習を効果的に活用する第一歩となります。
以下の表に、両者の違いを整理しました。
| 項目 | 分類 | 回帰 |
|---|---|---|
| 出力 | カテゴリ(離散値) | 数値(連続値) |
| 例 | スパム/非スパム、病気あり/なし | 売上予測、住宅価格予測 |
| 評価指標 | 正解率、F値、AUCなど | 平均二乗誤差(MSE)、平均絶対誤差(MAE) |
| ビジネスでの利用例 | 顧客の離脱予測、商品の需要分類 | 売上高の将来予測、在庫数の見積もり |
分類と回帰は一見似ているようでいて、解決する課題や評価基準が大きく異なります。
誤差を小さくする仕組み:損失関数と最適化
教師あり学習において、モデルの性能を左右する鍵となるのが「誤差をどう小さくしていくか」です。
この誤差を定量的に表すものが損失関数であり、予測値と正解ラベルの差を数値化する役割を持ちます。回帰問題では「平均二乗誤差(MSE)」がよく使われ、予測値と実際の値との差を二乗して平均することで、大きな誤差に対してより強くペナルティを与えます。
分類問題では「クロスエントロピー損失」が代表的で、正しいクラスに対して予測確率をどれだけ高められるかを評価します。
損失関数を小さくするために行われるのが最適化です。
最適化とは、モデルが持つパラメータ(重みやバイアス)を調整し、損失を最小化するように改良していく仕組みです。その中心的な手法が勾配降下法で、損失関数の傾きを計算し、傾きが小さくなる方向へ少しずつパラメータを更新していきます。モデルは学習を重ねるごとに予測精度を高めていきます。
金融の現場では、大量かつ複雑なデータを効率的に処理する必要があるため、勾配降下法を改良した「確率的勾配降下法(SGD)」や「Adam」といった手法がよく利用されます。これらの仕組みによって、教師あり学習モデルは膨大な市場データや顧客データに適用しても、現実的な時間で高精度な予測を実現できるのです。
教師なし学習とは?
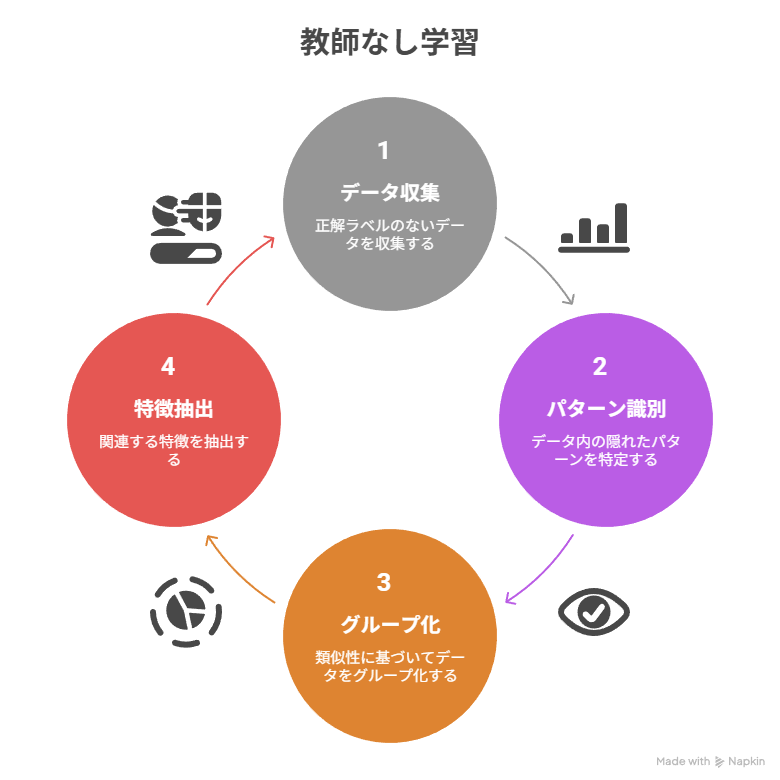
教師なし学習とは、正解ラベルが付与されていないデータを使って、隠れたパターンや構造を見つけ出す機械学習の手法です。
教師あり学習が「入力と答えのペア」をもとにモデルを育てるのに対し、教師なし学習は「入力データだけ」をもとにグループ分けや特徴抽出を行います。
代表的な手法としては、クラスタリングと次元削減があります。
クラスタリングでは、データを似た特徴を持つグループに分けます。例えば、顧客の購買履歴を分析して「価格重視型」「ブランド志向型」「まとめ買い型」といったグループを発見できれば、マーケティング戦略の最適化に役立ちます。
次元削減では、多数の特徴量から本質的な要素を抽出し、データを見やすく整理します。金融分野ではリスク要因の可視化やポートフォリオ分析に応用されています。
教師なし学習のメリットは、人間が気づきにくい潜在的な規則性をデータから発見できる点です。そのため、未知の不正取引パターンの検出や、潜在顧客層の発見に有効です。
「正解」が存在しないため、結果の良し悪しを判断するのが難しいという課題があります。金融分野で活用する際には、専門知識と組み合わせて解釈することが重要です。
クラスタリング入門:k-meansや混合ガウスモデル
クラスタリングは教師なし学習の代表的な手法で、データを似た特徴を持つグループに分けることを目的とします。
最も基本的なのが k-meansクラスタリング です。あらかじめクラスタ数を指定し、各データ点を最も近い中心に割り当ててグループを形成します。直感的で計算も高速なため、大規模データにも適用しやすいのが特徴です。
より柔軟な方法として 混合ガウスモデル(GMM) があり、データがどのクラスタに属するかを確率的に推定します。これにより、境界が曖昧なケースでも自然な分類が可能になります。
| 手法 | 特徴 | ビジネスでの活用例 |
|---|---|---|
| k-means | シンプル・高速、クラスタ数を事前に指定 | 顧客セグメント分析、購買パターン分類 |
| 混合ガウスモデル | 確率的に分類、曖昧な境界にも対応 | 金融リスクのパターン抽出、異常検知 |
階層的クラスタリング:デンドログラムで構造を可視化
クラスタリングの中でも、データをツリー状にまとめて関係性を示すのが 階層的クラスタリング です。
- 凝集型:近いデータ同士を結合していき、最終的に全体を一つのクラスタにまとめる。
- 分割型:大きなクラスタから始めて、徐々に細かく分割していく。
結果は デンドログラム(樹形図) で可視化され、どの段階でデータがグループ化されたかを直感的に把握できます。これは、自然分類や階層的な商品カテゴリの整理など、構造的な理解が必要な場面で役立ちます。
次元削減の基本:PCA・t-SNE・UMAPで高次元データをシンプルに
もう一つの重要な教師なし学習手法が 次元削減 です。
高次元データをより少ない次元に圧縮し、解析や可視化を容易にします。
- PCA(主成分分析):最も古典的な手法で、データの分散が最大となる方向を軸として射影。特徴量を減らしつつ本質を残す。
- t-SNE:非線形手法で、データの局所的な関係性を重視して低次元空間に配置。クラスタ構造を直感的に把握しやすい。
- UMAP:t-SNEより計算が速く、大規模データでも可視化しやすい。
| 手法 | 特徴 | 活用シーン |
|---|---|---|
| PCA | 線形でシンプル、計算が速い | 特徴量削減、前処理 |
| t-SNE | 非線形、局所構造を保持 | データ可視化、探索的分析 |
| UMAP | t-SNEより高速、解釈しやすい | 大規模データのクラスタ分析 |
これらは単独で用いられるだけでなく、クラスタリングの前処理として使われることも多く、複雑なデータから洞察を得る上で欠かせない技術です。
教師あり学習と教師なし学習の比較:メリット・デメリットと使い分け
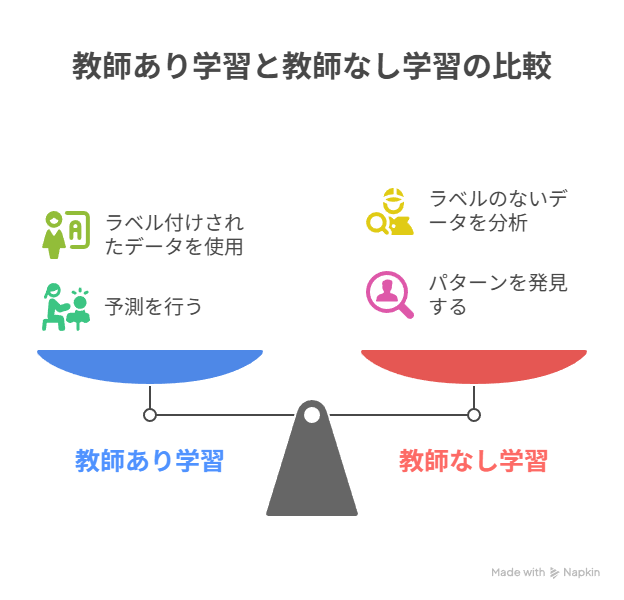
教師あり学習は、入力データと正解ラベルがセットになったデータを用いるため、「明確な予測」ができる点が最大の強みです。
融資審査における信用スコア予測や、不正取引の検知、株価の数値予測など、答えが定義されている問題に適しています。メリットは精度が高く、結果を数値で評価できるため改善もしやすいことです。大量の正解データを準備する必要があり、その作成やラベル付けにコストがかかるのが課題です。
教師なし学習は、ラベルなしデータから隠れた構造やパターンを発見できるのが特徴です。
顧客を購買傾向ごとにグループ化するセグメンテーションや、市場データの要因分析などに強みを持ちます。メリットは未知のパターンを見つけられる柔軟性にあり、特に新しい市場や不正取引の兆候を検出する際に有効です。ただし「正解」が存在しないため、結果の妥当性を評価しづらい点がデメリットとなります。
実務では、教師あり学習と教師なし学習を組み合わせるケースも少なくありません。教師なし学習で顧客をグループ分けし、その後に教師あり学習で各グループの購買予測モデルを構築する、といった流れです。
データの性質と目的に応じて手法を使い分けることが、機械学習を効果的に活用する鍵となります。
比較表:教師あり学習と教師なし学習
| 項目 | 教師あり学習 | 教師なし学習 |
|---|---|---|
| 必要なデータ | ラベル付きデータ | ラベル不要 |
| 得意なタスク | 予測(分類・回帰) | パターン発見、クラスタリング、次元削減 |
| 強み | 高い予測精度、実務に直結 | 柔軟性が高い、未知の構造を発見できる |
| 弱み | 大量のラベルデータが必要、コストが高い | 解釈が難しい、正解が一意に定まらない |
| ビジネスでの利用例 | 売上予測、需要予測、不正検知 | 顧客セグメンテーション、市場分析、新規顧客層の発見 |
教師あり学習の特徴
教師あり学習の最大の特徴は、「正解ラベルが存在するデータを利用する」という点にあります。
モデルは入力と出力の関係を明確に学習でき、実務で必要とされる予測や分類を高精度で実現できます。売上予測では過去の販売データと実際の売上額を学習し、将来の売上を推定できます。顧客の離脱予測では、過去の利用状況と離脱の有無をもとに、今後離脱する可能性を予測でき、不正取引検知では「正常」か「不正」かというラベルを使って取引の異常を検出するモデルを構築できます。
教師あり学習には大きな課題も存在します。それは「十分な量のラベル付きデータが必要になる」という点です。特に金融や医療の分野では、データ自体は膨大に存在しても、ラベル付けには専門知識が必要であり、作業コストが高くなります。
データの偏りがあると学習結果も偏ってしまい、現実の予測に使えないモデルになる可能性があります。
教師あり学習は、精度の高さとビジネス適用のしやすさという大きなメリットを持ちながらも、データ収集や整備にコストがかかる点を考慮する必要があります。
教師なし学習の特徴
教師なし学習の特徴は、「ラベルなしデータからパターンや構造を抽出できる」という点にあります。
あらかじめ正解が分からない状況でもデータの関係性を探索できるため、未知の知見を得ることに優れています。顧客セグメントの発見では、購買履歴や利用状況をもとに顧客を自然にグループ分けでき、マーケティング施策や商品開発に活用できます。
商品の購買傾向分析や市場データの要因抽出にも有効で、まだ明確な仮説がない段階の探索的分析に力を発揮します。
教師なし学習には課題もあります。正解ラベルが存在しないため、得られた結果が「妥当かどうか」を評価するのが難しく、解釈には専門知識やビジネスの文脈が欠かせません。同じデータでもアルゴリズムの選び方によって結果が大きく変わることもあり、「どのクラスタが正しいか」が一意に決まらないケースもあります。
教師なし学習は単独で完結させるのではなく、得られた構造をもとに仮説を立て、その後に教師あり学習や実務上の検証につなげることで、より実用的な成果を得られるのが特徴的な使い方といえます。
使い分けと応用例
機械学習を実務で活用する際、教師あり学習と教師なし学習を単独で使うのではなく、状況に応じて組み合わせることで効果を高める事例が増えています。
その代表例が「半教師あり学習」です。大量に存在するラベルなしデータを教師なし学習でグルーピングし、その結果を疑似的なラベルとして教師あり学習に取り込む方法です。金融分野では、顧客の取引パターンを教師なし学習で分類し、そのグループを活用して融資の返済可能性を予測するといった応用が可能になります。ラベル付きデータが不足していても精度を向上できる点が大きな利点です。
異常検知の領域では、両者の役割分担が特に有効です。まず教師なし学習で「通常の挙動」から外れるデータを見つけ出し、その後教師あり学習を使って「異常」か「正常」かを判定するという流れが一般的です。未知の不正取引やシステム障害の早期発見が可能となります。
このような使い分けは金融にとどまらず、医療では患者データの分類と診断支援、製造業では機械の故障予測や品質管理にも応用されています。
教師あり学習と教師なし学習を補完的に活用することで、ラベルの有無やデータの性質に応じた柔軟な分析が実現できるのです。
まとめ

本記事では、機械学習における二大アプローチである「教師あり学習」と「教師なし学習」について、その仕組みや代表的な手法、さらにビジネスへの活用方法を整理してきました。
改めて振り返ると、両者は入力データに「正解ラベル」が付与されているかどうかという点で明確に区別されます。
教師あり学習はラベル付きデータを活用することで高い予測精度を実現し、売上予測や不正検知、顧客離脱予測といった実務に直結する課題に強みを発揮します。
教師なし学習はラベルが不要で、潜在的なパターンやグループ構造を探索するのに優れており、顧客セグメンテーションや市場分析、新しい需要の発見といった場面で力を発揮します。
それぞれに強みと課題があり、教師あり学習はデータ収集・アノテーションにコストがかかる点が弱点であり、教師なし学習は結果の解釈が難しく、必ずしも「唯一の正解」が導けるわけではないという特性を持ちます。
実務の現場では両者を単独で使うよりも、補完的に組み合わせるアプローチが有効です。教師なし学習で顧客をクラスタリングし、そのラベルを教師あり学習の訓練データとして利用する「半教師あり学習」や、異常検知で両者を段階的に適用する手法などが代表例です。
機械学習の多様な技術を適材適所で組み合わせることで、より精度が高く実務に役立つモデルを構築することが可能となります。
今後、データ活用がさらに進む中で、企業や組織が競争力を高めるためには、教師あり学習と教師なし学習を単なる理論として理解するだけでなく、ビジネス課題に即した形で応用する視点が欠かせません。
正確な予測が必要な領域では教師あり学習、未知の構造を探索したい領域では教師なし学習を使い分け、さらに両者を組み合わせることで、新たな知見や価値を創出することができます。
機械学習の本質は「データから学習し、意思決定を支援すること」です。その多様なアプローチを理解し、適切に活用することこそが、これからの時代のビジネスパーソンに求められる重要なスキルといえるでしょう。





