
 カワセミ@金融ブロガー
カワセミ@金融ブロガーこんにちは。カワセミ@金融ブロガーです
近年、「人工知能(AI)」という言葉はニュースやビジネス、日常会話でも頻繁に登場するようになりました。
その中でも特に重要な分野として注目されているのが「機械学習(Machine Learning)」です。機械学習とは、コンピュータが明示的なプログラムを与えられなくてもデータからパターンを学習し、自動的に判断や予測を行う技術のことを指します。
AIという広い概念の中で、機械学習は中核的な役割を担っており、音声認識、画像認識、自然言語処理、レコメンドシステムなど、私たちの身近なサービスに数多く利用されています。
しかし、初めて学ぶ方にとっては、「人工知能と機械学習の違いは何か?」「どんな種類の学習モデルがあるのか?」といった基本的な疑問が浮かぶでしょう。機械学習は専門用語や数学的な概念が多く、全体像を直感的に理解するのが難しい分野でもあります。
そこで本記事では、AIと機械学習の関係を整理しつつ、学習モデルの基本構造、さらに機械学習の問題が大きく「分類(Classification)」と「回帰(Regression)」に分けられるという重要な視点を解説します。これらの理解は、後にディープラーニングや強化学習といった高度なテーマに進む際の土台となります。
本記事を読み終える頃には、機械学習の基本概念や種類、問題の分類方法を理解できるようになります。難しい内容はなるべく少なく、初心者でもスムーズに理解できるように解説します。
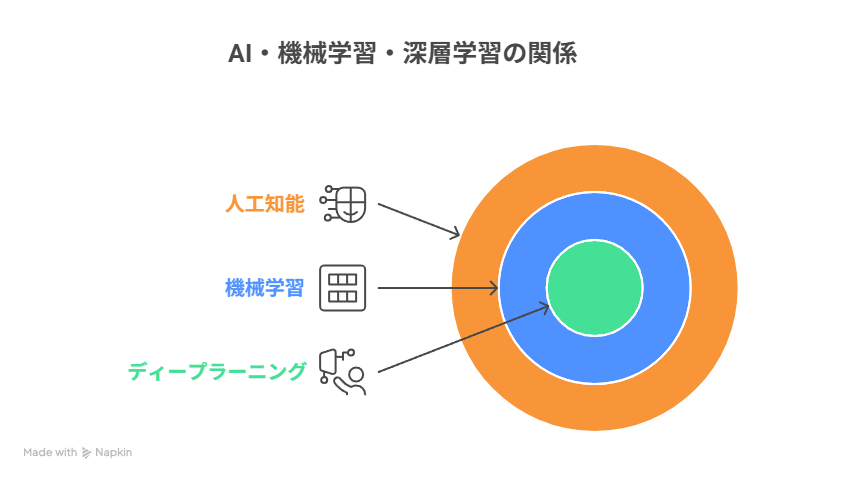
・まず先に人工知能と機械学習とディープラーニングの関係性を理解しておこう
人工知能(AI)は、人間の知的行動をコンピュータで再現するための総称です。その中に機械学習があり、さらに機械学習の中にはディープラーニング(深層学習)が含まれます。イメージとしては、AI > 機械学習 > ディープラーニングという階層構造になっており、すべてが同じ意味ではありません。
| 階層 | 説明 | 代表例 |
|---|---|---|
| AI(人工知能) | 人間の知的行動を模倣するシステム全般 | チャットボット、自動運転 |
| 機械学習 | データから学習して予測・判断を行う技術 | スパムメール判定、商品レコメンド |
| ディープラーニング | ニューラルネットワークを多層化した学習手法 | 顔認識、音声合成 |
それではここから細かく見ていきましょう。
機械学習と人工知能の違いを押さえる
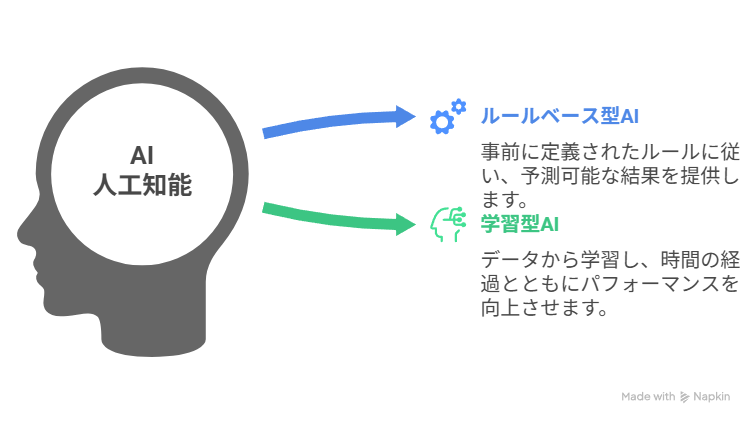
AI(人工知能)とは何か?その広い概念
AI(人工知能)は、単なるプログラムやアルゴリズム以上の存在として、「人間の知的活動を模倣・再現すること」を目的とした技術の総称です。
ここでいう知的活動には、自然言語を理解して会話する、画像や映像の中から対象物を識別する、与えられた情報から最適な行動を選択する、未知の問題に対して解決策を導くなど、幅広い分野が含まれます。
AIの中には、大きく分けて「ルールベース型」と「学習型」の2つがあります。
ルールベース型は、人間があらかじめ設定した条件や手順に従って動作します。たとえば「もしAならBを実行する」といった条件分岐が代表的で、医療診断支援システムや業務自動化ツールなどで利用されています。
一方、学習型は過去のデータを用いてパターンを学習し、経験を基に精度を高めていきます。これには機械学習や深層学習が含まれます。
つまりAIは必ずしも機械学習に依存しているわけではなく、目的や環境によって多様なアプローチが存在します。この広い概念を理解することで、AI技術の適用範囲や限界を正しく見極めることができます。
機械学習がAIの中で果たす役割
機械学習はAIの中核的な技術で、人間が逐一ルールを設定しなくても、コンピュータが経験的に知識を獲得できる点が特徴です。
与えられたデータをもとに、モデルは統計的手法やアルゴリズムを用いてパターンや関係性を見つけ出します。これにより、未知のデータに対しても高い精度で予測や分類を行えるようになります。
機械学習はAIを「静的な仕組み」から「成長し続ける仕組み」へと変える役割を果たします。ルールベースAIが事前に定義された知識の範囲内でしか動けないのに対し、機械学習は新たなデータが追加されるたびにモデルの精度を向上させ、環境や条件の変化にも柔軟に適応できます。
特長として多様な手法に分かれます。正解ラベル付きデータで学習する「教師あり学習」、正解のないデータから構造を見つける「教師なし学習」、試行錯誤を通じて最適な行動を学ぶ「強化学習」です。
これらは金融市場の予測、音声アシスタント、医療画像診断、自動運転車など、幅広い領域で実用化されています。
深層学習との関係と違い
深層学習は機械学習の一分野であり、従来の機械学習手法と比べて特徴量の設計を自動化できる点が大きな違いです。
深層学習では多層のニューラルネットワークが入力データから特徴量を自動的に学習し、より精緻なパターン認識を可能にします。多層構造の学習において膨大なパラメータを最適化する必要があります。高性能GPUや分散処理環境といった計算資源の進歩が、深層学習の発展を後押ししてきました。
機械学習全体の枠組みの中で見ると、深層学習は特に非構造化データ(画像、音声、テキストなど)の処理に強みを持ちます。
逆に、データ量が限られていたり、特徴量が明確に定義されている場合は、決定木やランダムフォレスト、サポートベクターマシンといった従来型の機械学習手法のほうが効率的なケースもあります。このように、深層学習は万能ではなく、データの性質や目的に応じた使い分けが重要です。
学習モデルの基本と種類

学習モデルとは?データとアルゴリズムをつなぐ仕組み
学習モデル(Machine Learning Model)とは、入力データを解析し、その結果をもとに予測や分類を行う計算の枠組みです。
モデルは、アルゴリズムによってデータから規則性やパターンを学習し、その知識を使って新しいデータに対する判断を行います。
住宅価格予測では「間取り・駅からの距離・築年数」などの特徴量を入力し、「価格」という結果を出力します。この過程で、モデルは「データ → 数学的関係 → 予測」という橋渡し役を担います。
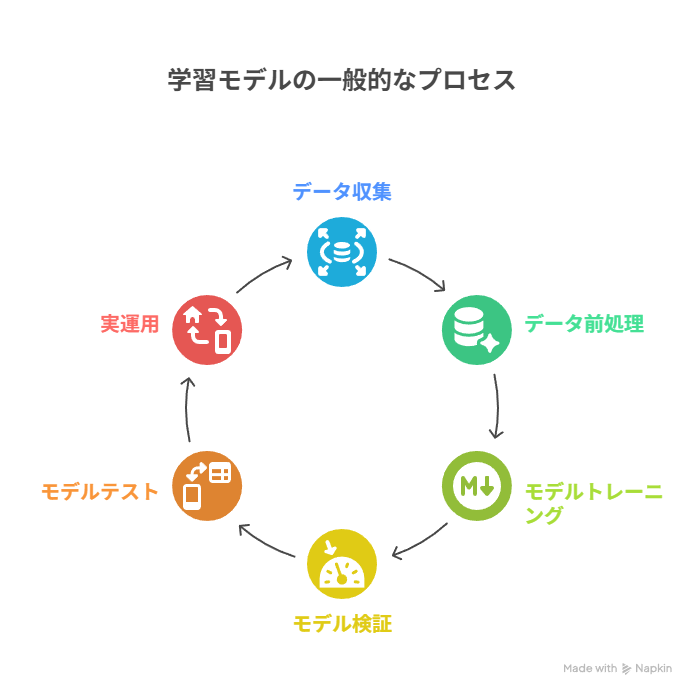
モデルの学習プロセスと評価方法
学習モデルの構築は、主に以下のステップで進みます。
- データ収集と前処理
欠損値補完、特徴量選択、スケーリングなどを行い、学習に適した形式に整えます。 - トレーニング(学習)
トレーニングデータを使ってモデルのパラメータ(係数や重み)を最適化します。 - 検証(バリデーション)
ハイパーパラメータ調整や過学習の検出に使用します。 - テスト(評価)
未知のデータに対してモデルの性能を確認します。精度(Accuracy)、適合率(Precision)、再現率(Recall)、F1スコアなどの指標で評価します。
特に重要なのが汎化性能(Generalization)の確保です。過学習(Overfitting)を防ぐため、データの分割や正則化、ドロップアウトなどの手法を活用します。
初心者が押さえておくべき主要モデル例
学習モデルには多数の種類がありました。初心者が理解しやすく、かつ多くの分野で応用される代表的なモデルは以下の通りです。
| モデル名 | 主な用途 | 特徴 |
|---|---|---|
| 線形回帰(Linear Regression) | 数値予測 | シンプルな構造で解釈性が高い |
| ロジスティック回帰(Logistic Regression) | 二値分類 | 出力を確率として解釈可能 |
| 決定木(Decision Tree) | 分類・回帰 | 視覚的に理解しやすく特徴量の重要度も分かる |
| ランダムフォレスト(Random Forest) | 分類・回帰 | 複数の決定木を組み合わせて高精度を実現 |
| k近傍法(k-NN) | 分類 | 学習フェーズがほぼ不要、直感的に理解できる |
これらのモデルを通じて、「モデルがどのようにデータを処理し、どんな出力を返すのか」を具体的に学ぶことができます。
機械学習の問題は「分類」と「機能」に分けられる
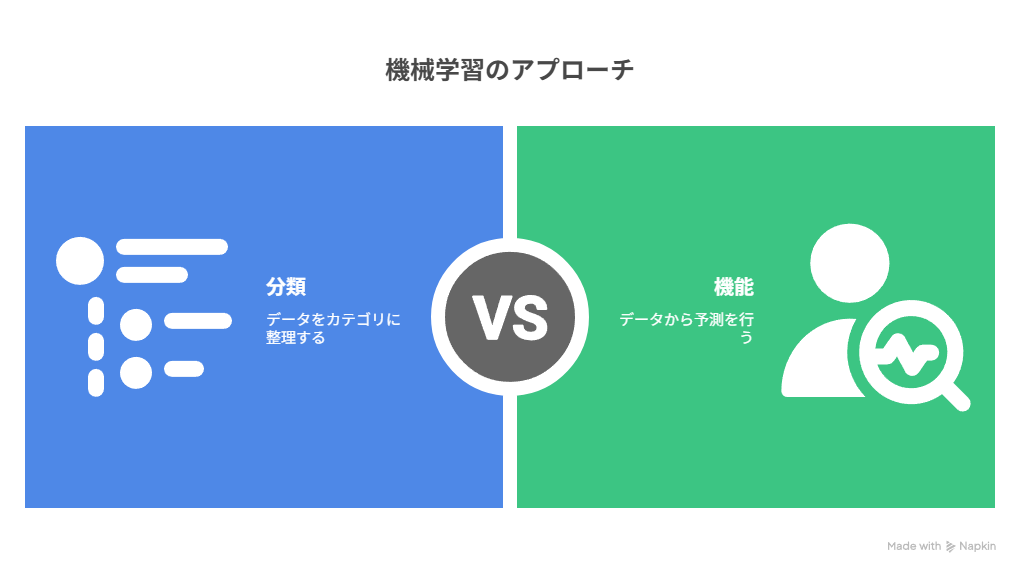
分類の視点:学習方法による3つのタイプ
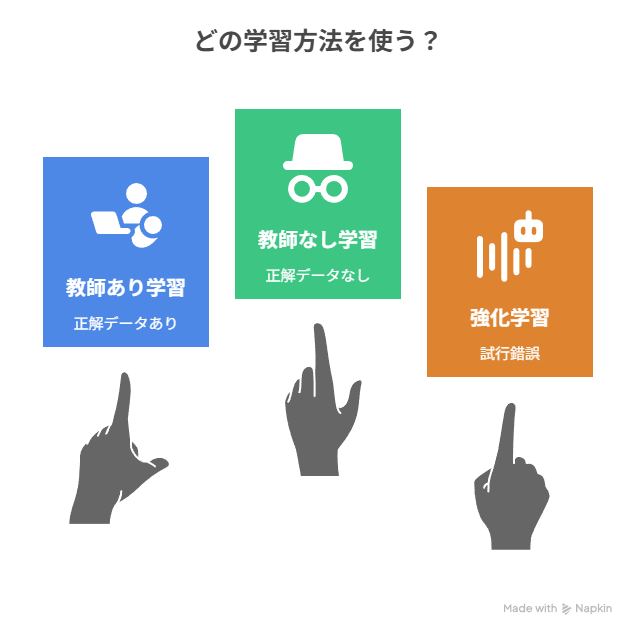
機械学習のアルゴリズムは、学習の仕方によって大きく3種類に分類できます。
- 教師あり学習(Supervised Learning)
- 特徴:正解ラベル付きのデータを使って学習します。
- 代表例:住宅価格予測、スパムメール判定、手書き文字認識
- メリット:精度が高く、結果を解釈しやすい
- 教師なし学習(Unsupervised Learning)
- 特徴:正解ラベルのないデータからパターンや構造を抽出します。
- 代表例:顧客セグメンテーション、購買パターン分析、クラスタリング
- メリット:未知の傾向や関係性を発見できる
- 強化学習(Reinforcement Learning)
- 特徴:エージェントが環境との試行錯誤を通じて報酬を最大化する行動を学びます。
- 代表例:自動運転、ゲームAI、ロボット制御
- メリット:動的で複雑な環境に適応可能
機能の視点:何を達成するための学習か
学習方法とは別に、「機械学習モデルが何を目的としているか」という機能別の分類も重要です。主な機能は以下の通りです。
| 機能 | 説明 | 代表例 |
|---|---|---|
| 予測(Prediction) | 数値や将来の状態を予測する | 売上予測、株価予測、需要予測 |
| 分類(Classification) | データをカテゴリに分類する | スパム判定、疾病診断 |
| 異常検知(Anomaly Detection) | 通常とは異なるパターンを発見する | 不正取引検出、センサー異常検出 |
| 推薦(Recommendation) | 個々のユーザーに最適な提案を行う | 商品レコメンド、動画推薦 |
両視点から見る代表的な応用事例
実際のビジネスや産業分野では、「学習方法」と「機能」の両方の視点を組み合わせて活用します。
- 金融業界
- 学習方法:教師あり学習
- 機能:異常検知(不正取引の発見)、予測(市場動向予測)
- 小売業界
- 学習方法:教師あり学習+教師なし学習
- 機能:需要予測、顧客セグメンテーション、商品レコメンド
- 製造業
- 学習方法:教師あり学習
- 機能:故障予測、品質検査の自動化
- 医療分野
- 学習方法:教師あり学習+教師なし学習
- 機能:疾患分類、異常検知(早期診断)、個別化医療の提案
機械学習を理解するためのステップ参考例
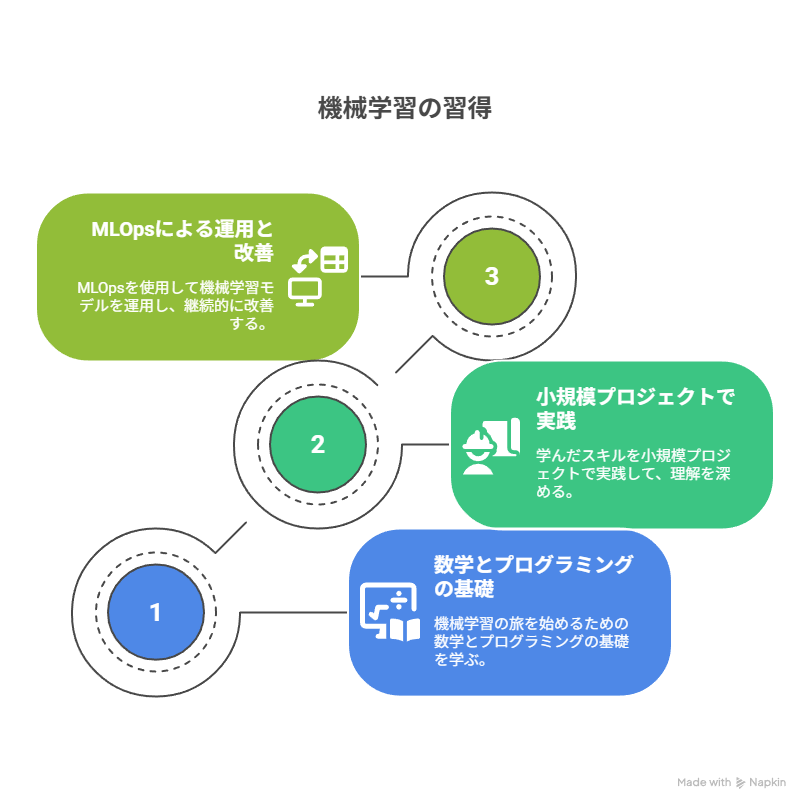
機械学習に興味がある方向けに「習得ステップ」を考えました。
以下の内容に沿って機械学習について学んでいけば実務レベルで活用できることでしょう。
・本気で機械学習を習得したい方向けの内容です。
学ぶべき基礎知識(数学・プログラミング・統計)
機械学習を効果的に学ぶには、まず基礎的な理論とスキルを固めることが重要です。特に以下の分野は必須となります。
| 分野 | 主な内容 | 学習のポイント |
|---|---|---|
| 数学 | 線形代数(行列計算、ベクトル)、確率統計(確率分布、推定)、微分積分(勾配、最適化) | モデルの仕組みやアルゴリズムの理解に不可欠 |
| プログラミング | Pythonの基本文法、データ処理(Pandas、NumPy) | 実際のデータ分析やモデリングに直結 |
| 機械学習ライブラリ | scikit-learn、TensorFlow、PyTorch | モデル構築や学習プロセスを効率化 |
これらの基礎を押さえておくことで、単にコードを書くだけでなく「なぜそのモデルが動くのか」を理解でき、応用力が飛躍的に向上します。
小規模プロジェクトで学習モデルを試す方法
基礎を学んだら、次は小さな成功体験を積むことが大切です。大規模で複雑な案件にいきなり挑むよりも、まずは公開されているシンプルなデータセットで試すのが効果的です。有名なデータセットは以下のようなものがあります。
- Irisデータセット
花の種類を分類する有名なデータセット。分類問題の入門に最適。 - Titanicデータセット
乗客の生存予測を行う。前処理からモデル構築まで一通り体験できる。 - MNISTデータセット
手書き数字の画像認識。ディープラーニングの入門教材として人気。
これらを使って、データの読み込み → 前処理 → モデル学習 → 評価 という一連の流れを実践し、学んだ理論をコードに落とし込みましょう。
実務で活用するための次の一歩
学習モデルをビジネスに導入する場合、作って終わりではなく、運用面での体制整備が求められます。特に重要なのがMLOps(Machine Learning Operations)です。
- 再現性:同じコード・データでいつでも同じ結果が得られる状態を確保
- 監視:モデルの精度低下やデータの変化(データドリフト)を早期発見
- 自動化:学習・評価・デプロイのパイプライン化
これにより、モデルが長期的に安定してビジネス価値を提供できるようになります。
まとめ

機械学習は、人工知能(AI)の中でもデータから学習し、経験を積むことで性能を高める中核的な技術です。
AIという大きな枠組みの中で、ルールベース型では対応しきれない未知のケースにも柔軟に対応できるのが機械学習の強みです。そのため、ビジネス、産業、日常生活のあらゆる領域で急速に活用が進んでいます。
理解を深めるためには、まず人工知能と機械学習の違いを正しく整理し、次に学習モデルの構造や動作原理を押さえることが重要です。さらに、「分類(教師あり・教師なし・強化学習)」と「機能(予測・分類・異常検知・推薦)」という2つの視点で全体像を捉えることで、より実践的な知識へとつながります。
機械学習の主な応用事例(分類×機能の視点)
| 分野 | 学習方法 | 機能 | 代表例 |
|---|---|---|---|
| 金融 | 教師あり学習 | 異常検知・予測 | 不正取引検出、市場予測 |
| 小売 | 教師あり+教師なし | 予測・推薦 | 需要予測、レコメンドエンジン |
| 製造 | 教師あり学習 | 予測 | 故障予測、品質検査 |
| 医療 | 教師あり+教師なし | 分類・異常検知 | 疾患診断、早期発見 |
学習を始める際は、数学・統計・プログラミングの基礎を固め、小規模プロジェクト(IrisやTitanicなどのデータセット)で実践することが有効です。こうしたステップを踏むことで、コードの書き方だけでなくモデルの仕組みや適用範囲を理解できるようになります。そして、実務ではMLOps(再現性の確保、モデル監視、パイプライン化)を導入し、長期的に活用できる体制を整えることが重要です。
機械学習は今後も需要が拡大する成長分野です。今のうちに全体像を把握し、基礎から実務レベルまでの流れを理解しておくことは、将来のキャリアやビジネス競争力に直結します。早期に学び始めた人ほど、AI時代の波に乗りやすくなります。




