
 カワセミ@金融ブロガー
カワセミ@金融ブロガーこんにちは。カワセミ@金融ブロガーです
強化学習は、機械学習の中でも近年特に注目を集めている分野です。囲碁や将棋のAI、ロボットの制御、さらには自動運転やレコメンドシステムまで、多様な領域で成果を挙げています。
強化学習の特徴は「正解ラベルが存在しない」点にあります。
教師あり学習が答えを参照しながら学習するのに対し、強化学習ではエージェント(agent)が環境と相互作用し、自らの行動の結果から報酬(reward)を受け取り、その報酬を最大化するように学習を進めます。
学習の流れはシンプルで、まず状態(state)を観測し、そこから行動(action)を選択し、環境から得られる報酬を評価する、というサイクルを繰り返します。この試行錯誤を通じて方策(policy)が改善され、長期的により高い収益(return)を得られるようになります。また、エピソード(episode)と呼ばれる一連の経験のまとまりを通じて、価値を表す指標であるV値やQ値を計算し、行動選択の質を高めるのも重要なポイントです。
強化学習を理解することは、単なる理論学習にとどまらず、実社会での応用を考える上でも大きな意味があります。
ロボティクス分野では複雑な環境での最適な動作を自律的に学習でき、推薦システムではユーザー体験を最適化するアルゴリズムとして活用されています。
初めて強化学習について学ぶと難しく感じられる概念も多いですが、基本要素である「状態・行動・報酬」の関係を押さえることが理解の第一歩となります。
強化学習とは何か
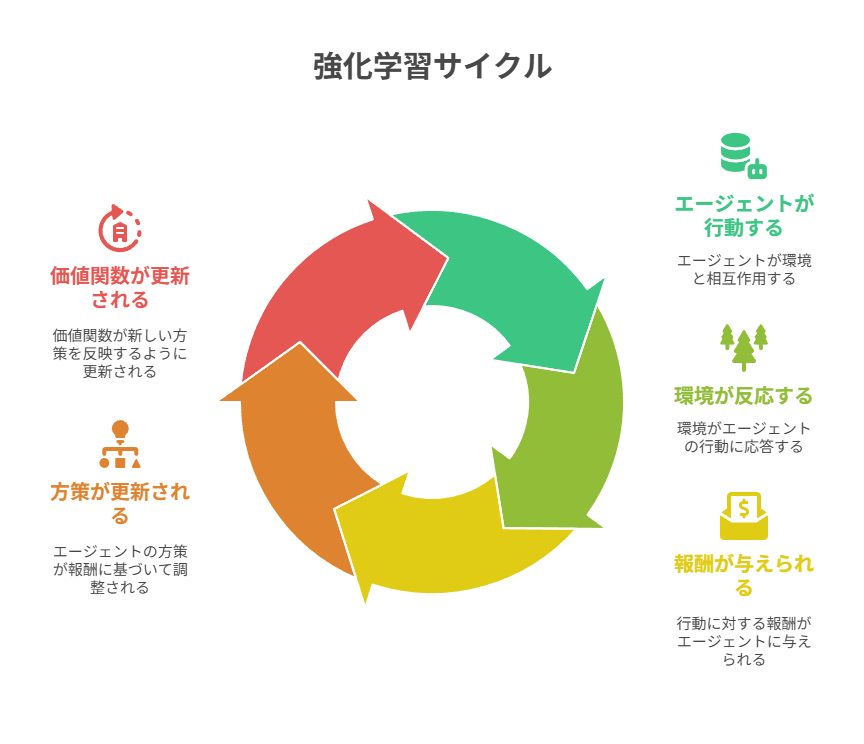
強化学習は、機械学習の中でも「逐次的な意思決定」を対象とする学習方法です。
教師あり学習が入力とラベルの対応を学習するのに対し、強化学習では未来の報酬まで考慮した行動系列を最適化します。一度の正解を当てるのではなく、長期的に最も大きな利益を得る行動方針を見つけることが目的です。
基本的な構成要素は、エージェント(agent)、環境(environment)、報酬(reward)、方策(policy)、収益(return)、価値関数の6つであり、これらはエピソード(episode)を通じて繰り返し更新されます。
表:機械学習の他手法との比較
以下の表は、強化学習と教師あり学習・教師なし学習の違いを整理したものです。
| 手法 | 学習の仕組み | 特徴 | 応用例 |
|---|---|---|---|
| 教師あり学習 | 入力とラベルを用いて学習 | 正解データが必要 | 画像分類、音声認識 |
| 教師なし学習 | ラベルなしデータから構造を抽出 | パターン発見に強い | クラスタリング、次元削減 |
| 強化学習 | 環境との相互作用を通じて報酬を最大化 | 試行錯誤から学習 | ゲームAI、ロボティクス、自動運転 |
環境とエージェント(agent)の関係
強化学習の中心は「エージェント」と「環境」の相互作用にあります。
時刻tにおいて、エージェントは「状態state_t」を観測し、方策(policy)に基づいて「行動action_t」を選択します。その行動に応じて環境は次の「状態state_{t+1}」と「報酬reward_t」を返し、これが収益(return)の源となります。
観測可能な情報の範囲や、報酬が遅れて与えられるかどうか、また状態遷移が確率的か決定的かによって問題の難易度は大きく変化します。タスク設計時には「観測可能な情報は何か」「制御可能な範囲はどこまでか」を最初に定義することが重要です。
マルコフ決定過程(MDP)の直観
強化学習の多くはマルコフ決定過程(MDP)の枠組みで定式化されます。
MDPでは「次の状態と報酬は、現在の状態と行動のみに依存する」というマルコフ性を仮定します。この単純化により、価値関数を使った動的計画法やベルマン方程式を適用でき、理論的に最適な方策を導くことが可能になります。
現実の問題では完全なマルコフ性が成り立たないことも多く、その場合は履歴情報を要約して扱ったり、RNNを活用した部分観測マルコフ決定過程(POMDP)での拡張が用いられます。
タスクの種類:逐次決定とオンライン学習
強化学習は連続的に意思決定を行う逐次決定問題です。
静的なデータセットを前提とする教師あり学習とは異なり、エージェント自身の行動によってデータが生成されるため、オンライン学習の性質を強く持っています。
探索と利用のバランスを取る「探索戦略」が不可欠であり、方策改善と同時に設計されなければなりません。特に複雑な環境では、効率的な探索が学習の成否を左右します。
基本概念:状態(state)・行動(action)・報酬(reward)
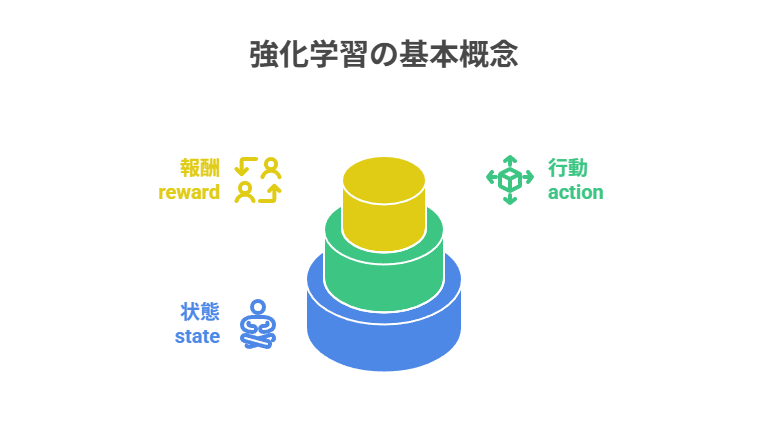
強化学習は、機械学習の中でも特に「試行錯誤による学習」に特徴があります。
その中心にあるのが、状態(state)、行動(action)、報酬(reward)という3つの基本概念です。
状態はエージェントが意思決定に利用する情報、行動はその情報に基づいて選択される介入、報酬は行動の良し悪しを即時的に評価する指標です。この定義が不明確だと、価値関数(Q値やV値)の推定が不安定になり、学習の進行に悪影響を及ぼします。
実務においては、観測可能なログを適切に状態へ対応づけ、目的となるKPIを報酬設計に落とし込むことが成功の鍵となります。また、報酬の粒度を早期に設計することで、学習の効率を大幅に高められます。
表:基本概念の比較表
以下は、状態・行動・報酬の役割を整理した表です。
| 概念 | 定義 | 設計のポイント | 典型的な注意点 |
|---|---|---|---|
| 状態 (state) | 意思決定に必要な情報 | 将来の報酬に関わる特徴のみを選択 | 不要な特徴の追加で探索が非効率に |
| 行動 (action) | エージェントが選択する介入 | 離散か連続かを明確化 | スケーリング不足や制約違反 |
| 報酬 (reward) | 行動の即時的な評価 | 最小限かつ一貫性ある設計 | 複雑すぎる設計で報酬ハッキング |
状態(state)の設計と特徴量抽出
状態は「将来の報酬に関連する情報のみ」を含むのが理想的です。
余分な特徴を含めすぎると探索空間が広がりすぎて学習が非効率になり、逆に情報が不足していると方策(policy)学習が難しくなります。
状態設計では正規化や離散化、スケーリングの調整を行うことが重要です。時系列データを扱う場合は、直近の履歴をウィンドウ化してまとめ、「state」として表現する手法も有効です。長期的な依存関係を考慮しやすくなります。
行動(action)空間:離散・連続の扱い
行動空間は大きく「離散」と「連続」に分かれ、それぞれに適したアルゴリズムがあります。
離散行動ではQ-learningやDeep Q-Network(DQN)が代表的で、ゲームAIやシンプルな操作環境に適しています。連続行動空間を扱う場合は方策勾配系アルゴリズム(例:DDPG、SAC、PPO)が有効です。連続空間では、行動のスケーリングやクリッピングが学習の安定性に直結するため注意が必要です。
実務で利用する場合は安全性を確保するために行動制約や業務上の条件を事前に組み込むことが求められます。
報酬(reward)設計のコツと罠
報酬設計は強化学習の中で最も難しい要素の一つです。
理想的な報酬は「望ましい行動を直接促す最小限の信号」です。複数の目標を扱う場合は重み付けを行い、報酬スケールを統一する必要があります。過度に複雑な設計は「報酬ハッキング」を招き、本来意図しない行動が強化されるリスクがあります。
学習初期に形勢判断用の中間報酬を与え、方策が安定してきた段階で徐々に削減していく手法も効果的です。
収益(return)・価値関数の考え方

強化学習の学習目標は「将来得られる報酬の合計を最大化すること」です。
これを定量的に表す指標が収益(return)であり、その期待値を近似する仕組みが価値関数です。価値関数には、状態そのものを評価するV値(状態価値関数)と、状態と行動の組み合わせを評価するQ値(行動価値関数)の2種類があります。
適切な割引率γ(ガンマ)を選び、どの程度未来の報酬を重視するかを調整することで、短期的な成果と長期的な最適化のバランスを制御できます。これはゲームAIからロボティクスまで、あらゆる応用分野で重要な設計要素となります。
表:V値とQ値の比較表
以下の表に、V値とQ値の違いを整理しました。
| 指標 | 定義 | 評価対象 | 応用例 |
|---|---|---|---|
| V値 (状態価値関数) | 特定の状態における将来収益の期待値 | 状態のみ | 方策評価、状態の安定性分析 |
| Q値 (行動価値関数) | 状態と行動の組における将来収益の期待値 | 状態+行動 | 行動選択、Q-learning、DQN |
収益(return)と割引率γの意味
収益は次のように定義されます。
・G_t = Σ{k=0}^∞ γ^k r{t+k+1}
ここでγは割引率と呼ばれるハイパーパラメータです。γが小さい場合は直近の報酬を重視する「短期志向」となり、γが大きい場合は将来の報酬も重視する「長期志向」になります。
広告配信の最適化では短期のクリックを重視し、ロボットの制御や自動運転では長期的な安全性や効率を重視するなど、ドメインごとにγの適切な設定が異なります。学習曲線を観察しながら微調整するのが実務的なアプローチです。
V値(V-value)と状態価値関数
V値は「特定の状態がどれだけ良いか」を測る尺度です。形式的には
・V^π(s) = E[G_t | S_t=s, π]
と定義され、状態sにおける将来の期待収益を表します。V値の推定が安定すると方策改善が進みやすくなります。
実装では表形式による管理、線形関数近似、ニューラルネットワークを用いた非線形近似などさまざまな方法があり、バイアスとバリアンスのバランスを取りながら正則化を行うことが重要です。
Q値(Q-value)と行動価値関数
Q値は「状態と行動の組(s,a)の価値」を表す指標で、次のように定義されます。
・Q^π(s,a) = E[G_t | S_t=s, A_t=a, π]
離散的な行動空間では「Q値が最大となる行動を選択する」ことがそのまま最適方策につながります。Q値は過大推定を起こしやすいため、Double Q-learningやターゲットネットワークといった改良手法が導入されます。
ベルマン方程式の直観と分解
価値関数の根底にあるのがベルマン方程式です。価値は「即時の報酬+次の状態における割引価値」という形で再帰的に表されます。
・V^π(s) = E[r + γV^π(s’)]
・Q^π(s,a) = E[r + γE_{a’∼π}[Q^π(s’,a’)]]
この分解が動的計画法、時間差(TD)学習、価値反復などの強化学習アルゴリズムの基盤となります。
方策(policy)の探索と活用

強化学習の核心は「既知の良い行動をどの程度活用するか」と「未知の行動をどこまで探索するか」のバランスにあります。
方策(policy)とは、状態に基づき行動を選択する確率分布のことです。この分布をどのように設計・調整するかによって、収益(return)の伸び方や学習速度が大きく変わります。
機械学習の他分野と異なり、強化学習では試行錯誤を通じて自らデータを生成するため、探索パラメータ(εや温度など)の管理が特に重要になります。
表:探索戦略の比較表
以下に代表的な探索戦略の特徴を整理しました。強化学習の設計段階でどの方策を選択すべきか判断する参考になります。
| 手法 | 仕組み | 長所 | 短所 |
|---|---|---|---|
| ε-greedy | 一定確率でランダム行動を選択 | 単純で実装容易 | 効率的な探索が難しい |
| ソフトマックス | 行動価値を確率分布化し温度で制御 | 探索度合いを滑らかに調整 | 温度設定が難しい |
| UCB | 信頼区間を利用して不確実性を評価 | 理論的に効率的な探索 | 計算コストが高い場合あり |
決定的方策と確率的方策
方策は大きく「決定的」と「確率的」に分類できます。
決定的方策は、ある状態に対して常に一意の行動を出力する方式です。確率的方策は行動の分布を出力し、その確率に従って行動を選びます。
連続制御の領域では、決定的方策に探索ノイズを加える方法が多く使われます。離散行動の場合は、確率的方策が柔軟で扱いやすいことが多いです。安全制約のある環境では、リスクを分散できる確率的方策が有効です。
ε-greedy・ソフトマックス・UCBの比較
探索戦略にはさまざまな手法があります。
・ε-greedyは「一定の確率εでランダム行動を選択する」シンプルな方法で、計算コストが低く強力です。
・ソフトマックス方策は温度パラメータを調整することで、探索度合いを滑らかにコントロールできます。
・UCB(Upper Confidence Bound)は不確実性に基づいて行動を選択するため、効率的な探索が可能です。
環境のノイズ特性や報酬(reward)のスケールに応じてこれらを使い分けることが推奨されます。学習が進むにつれてεや温度を段階的に減衰させると、探索から活用への自然な移行が可能となります。
方策のパラメータ化:関数近似とディープ化
方策を実装する際には、関数近似を用いて行動選択をモデル化します。
線形関数近似は解釈性と安定性に優れており、小規模問題や特徴量設計が明確な場面で有効です。これに対し、ニューラルネットワークを利用したディープ方策は高次元の状態(state)を扱う場面で強力です。
表現力が高い分、学習の不安定化や発散のリスクがあるため、正則化や勾配クリッピング、ガウス分布の分散下限の設定などが必須となります。価値推定と方策学習を組み合わせたActor-Critic手法は、表現学習と安定性を両立できるため実務でも広く採用されています。
主要アルゴリズム早見:価値ベースと方策ベース
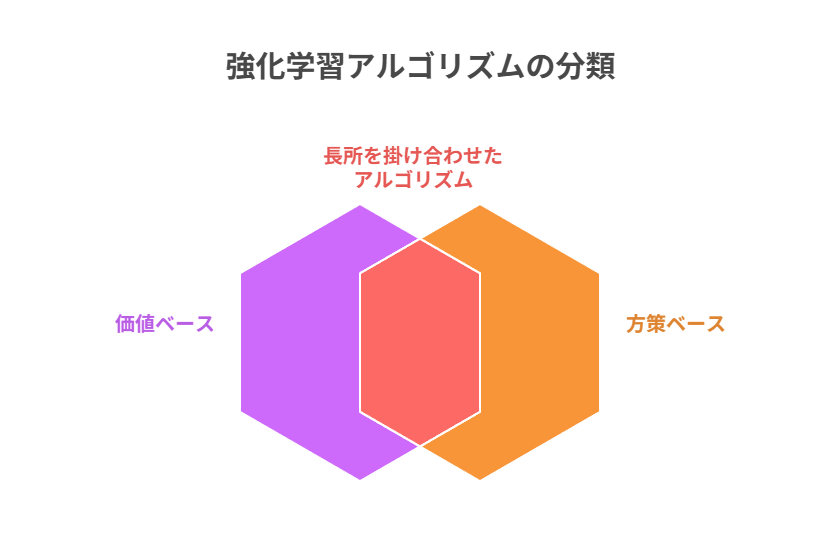
強化学習のアルゴリズムは大きく「価値ベース」と「方策ベース」に分けられます。
価値ベース手法はQ値やV値といった価値関数を推定し、その結果から方策を導きます。方策ベース手法は方策を直接最適化し、確率分布を更新していきます。
この両者の長所を組み合わせたのがActor-Critic系手法であり、サンプル効率と学習の安定性を両立させることが可能です。
現代の強化学習研究や応用では、この三本柱が基本的な流れを形成しています。
表:アルゴリズム比較表
以下の表に、主要な強化学習アルゴリズムの特徴をまとめました。
| アルゴリズム | 分類 | 特徴 | 応用例 |
|---|---|---|---|
| モンテカルロ法 | 価値ベース | バイアスが少ないが分散が大きい | 小規模なエピソード環境 |
| TD学習 | 価値ベース | 逐次更新で効率的、ただしバイアスあり | ロボティクス制御、シミュレーション |
| SARSA | 価値ベース(オンポリシー) | 安定性重視、探索方策依存 | 安全性が求められる制御 |
| Q-learning | 価値ベース(オフポリシー) | 最適方策に収束しやすい | ゲームAI、自律エージェント |
| DQNファミリー | 価値ベース+深層学習 | 高次元入力を扱える | Atariゲーム、画像ベース制御 |
| 方策勾配 | 方策ベース | 方策を直接更新、連続行動に強い | 連続制御、自動運転 |
| Actor-Critic | ハイブリッド | サンプル効率と安定性の両立 | 複雑なロボティクス、産業応用 |
モンテカルロ法とTD学習(Temporal Difference)
モンテカルロ法(MC)はエピソード終了後に収益(return)を計算し、それを基に価値関数を更新します。
時間差学習(TD)は部分的な推定値を用い、逐次的に更新します。
MCは分散が大きい反面バイアスが少なく、TDは分散が小さい一方でバイアスが大きいという特徴があります。n-step TDやλ-returnを導入することで、両者のメリットを折衷することが可能です。
SARSAとQ-learningの違い
SARSAとQ-learningはいずれもQ値を更新する手法ですが、アプローチが異なります。
SARSAはオンポリシー型で、実際に選択した行動に基づいてQ値を更新します。これにより探索戦略の影響を直接受けるため、安全性や安定性が高い反面、最適性はやや犠牲になります。
Q-learningはオフポリシー型で、次状態における最大Q値を用いて更新するため、理論的には最適方策に収束しやすいですが、探索の設計次第で学習が不安定になることもあります。
DQNファミリー:経験再生・ターゲットネットワーク
Deep Q-Network(DQN)はディープラーニングを利用してQ値を近似する代表的なアルゴリズムです。
経験再生(Replay Buffer)によって相関を断ち切り、ターゲットネットワークを導入して収束を安定化させます。その後、Double DQNでQ値の過大推定を抑え、Dueling Networkで状態価値とアドバンテージを分離し、表現力を高めました。
優先度付き経験再生を導入することで、重要な経験を効率的に学習できるようになっています。
方策勾配・Actor-Critic・A2C/A3Cの概要
方策勾配法は、期待収益の勾配を直接計算して方策を最適化するアプローチです。
Actor-Critic手法では、Actorが方策を更新し、Criticが価値関数を推定することで安定性を向上させます。進化版のA2C(Advantage Actor-Critic)やA3C(Asynchronous Advantage Actor-Critic)は、並列環境でサンプルを収集し、分散学習によって効率性と安定性を高めています。
エントロピー正則化を導入することで、探索を維持しつつ多様な行動選択を促す工夫も行われています。
エピソード(episode)設計と学習スキーム
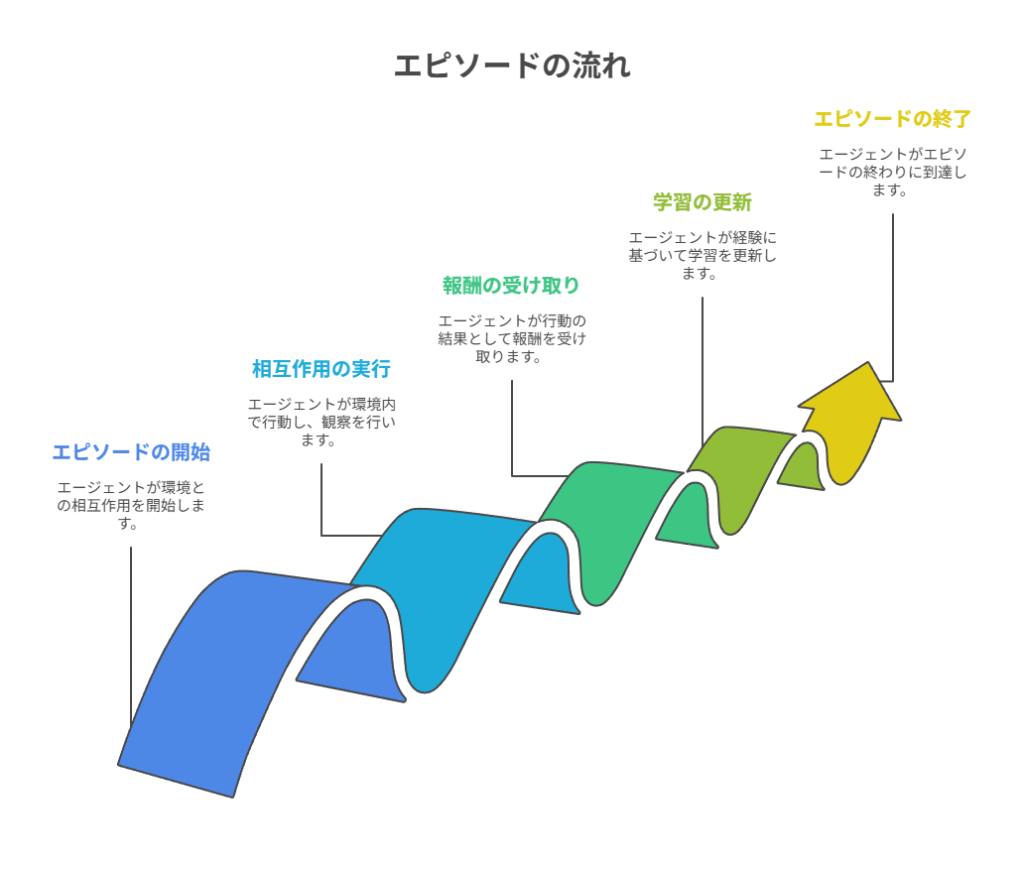
強化学習における学習は、エピソードという単位で管理されます。
エピソードとは、初期状態から終端状態に到達するまでの一連の相互作用のことです。ゲームであれば「スタートからゲームオーバーまで」が1エピソードに相当します。
バンディット問題のように単発で完結する設定でも、擬似的にエピソードを定義すると進捗や収束度合いの管理が容易になります。エピソードの長さやリセット条件は学習の難易度に大きく影響し、設計上の重要なハイパーパラメータの一つといえます。
表:学習スキーム比較表
以下の表に、オンポリシー/オフポリシーと、バッチ/オンライン学習の特徴を整理しました。
| 分類 | 特徴 | 長所 | 短所 |
|---|---|---|---|
| オンポリシー | 最新の方策で得たデータを使用 | 安定性が高い、理論解析が容易 | サンプル効率が低い |
| オフポリシー | 過去や他方策のデータも利用 | サンプル効率が高い | 補正が必要で安定性に課題 |
| オンライン学習 | 逐次的に更新 | 環境変化に即応できる | 変動が大きく収束が遅れることも |
| バッチ学習 | 一定量のデータでまとめて更新 | 安定性と再現性が高い | 即応性に欠ける |
エピソードとステップ:エピソード長の扱い
エピソードが長いほど、将来の収益(return)を正確に推定できる利点があります。
その分サンプルの分散が大きくなり、学習が不安定になりやすいという課題があります。実務では、最大ステップ数や早期打ち切り条件を設定することが一般的です。
学習初期には短いエピソードで安定性を確保し、収束が進んだ段階で徐々に長くする「段階的戦略」が有効です。こうした設計はロボティクスやシミュレーション環境でもよく利用されます。
オンポリシー vs オフポリシー
エピソード設計と密接に関わるのが、オンポリシーとオフポリシーの違いです。
オンポリシー学習は最新の方策で得たデータのみを用いるため、バイアスが少なく理論的に安定した更新が可能です。収集したデータを効率よく再利用できないため、サンプル効率は低くなりがちです。
オフポリシー学習は過去のデータや他の方策で収集したデータも活用できるため効率的ですが、重要度サンプリングなどの補正を導入しないと推定が歪むリスクがあります。
バッチ学習・オンライン学習と収束性
強化学習の学習スキームは、バッチ型とオンライン型に大別されます。
オンライン学習はステップごとに即時更新するため、環境の変化に迅速に適応できます。バッチ学習はまとめて更新するため安定性と再現性が高いという利点があります。
ミニバッチ学習を用いることで両者の長所を取り入れるのが一般的です。学習率、ターゲットネットワークの更新間隔、リプレイバッファのサイズなどを組み合わせて調整し、収束性と効率を両立させます。
実務応用と設計パターン
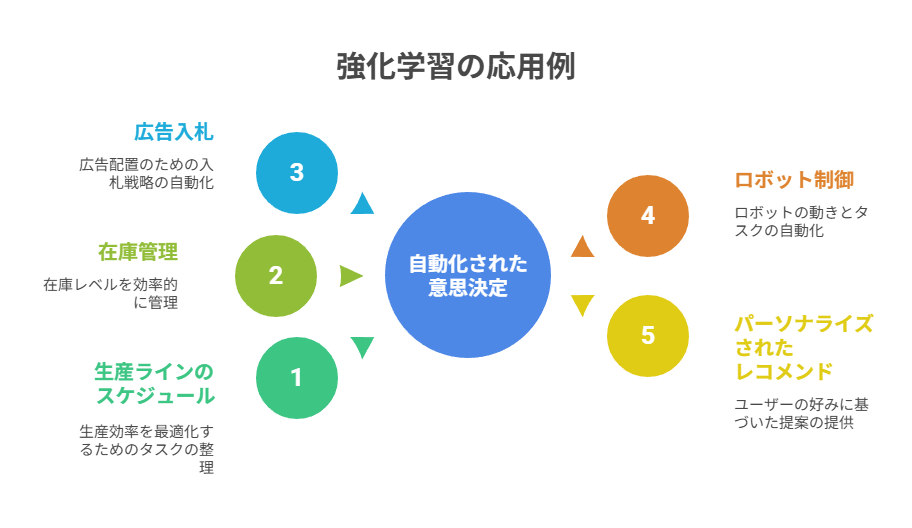
強化学習は、機械学習の中でも特に「意思決定の自動化」に強みを持つ分野です。人間が経験やルールベースで判断していた複雑なタスクに対して、エージェントが試行錯誤を通じて最適な行動方策を獲得できます。
典型的な応用領域としては、生産ラインのスケジュール、在庫管理、広告入札、ロボット制御、パーソナライズされたレコメンドなどが挙げられます。
Q値や方策(policy)の枠組みを実務のKPIと結び付ける設計が成功の鍵になります。実際の導入では安全性や制約条件を無視すると、事業インパクトよりもリスクが大きくなるため、KPIとの整合性を意識した設計が必須です。
表:実務応用領域の整理表
以下に強化学習の代表的な応用事例を整理しました。
| 領域 | 応用例 | 設計上のポイント |
|---|---|---|
| レコメンド | クリック予測、購買促進 | セッションをエピソード化、短期報酬と長期価値の両立 |
| 広告入札 | リアルタイム入札戦略 | 予算制約を考慮、return最大化とリスク管理 |
| ロボティクス | 自律移動、把持動作 | 連続action向け方策ベース手法、シミュレーション転移 |
| 在庫・物流 | 需要予測、配送最適化 | 長期return重視、制約条件の組み込み |
| 医療・金融 | 治療計画、投資戦略 | 安全制約とリスク管理が最重要 |
レコメンド・広告入札・ロボティクスの事例
強化学習は分野ごとに異なる形で活用されています。
レコメンドシステムでは、ユーザーセッションを1つのエピソードとして定義し、クリックや購買をrewardとして扱います。広告入札では、限られた予算の中で最大のreturnを得るために「制約付き最適化」が求められます。ロボティクスでは連続的な行動(action)が必要となり、SAC(Soft Actor-Critic)やTD3といった方策ベースの手法がよく用いられます。
実機に直接適用する前に、シミュレータで学習させてから転移学習を行うのも定石です。
安全性・制約付き強化学習の考え方
実務では「安全性をいかに担保するか」が大きな課題となります。
制約付き強化学習では、報酬最大化だけでなくコスト関数や安全制約を導入し、違反確率を一定以下に抑える設計が行われます。リスク感度の高い領域(例:医療、金融、インフラ制御など)では、確率的方策に境界を設けたり、探索中の行動を監視したりする必要があります。
オフラインRLで過去データから初期方策を学習し、人手によるポリシーを組み合わせることで、初期段階から安全性を担保することが可能です。
スパース報酬とカリキュラム学習
報酬が稀にしか得られない「スパース報酬問題」も実務で頻出します。
模倣学習や教師あり学習を利用して初期方策を暖機するのが効果的です。カリキュラム学習を導入し、簡単な目標から段階的に難易度を上げていくことで探索を効率化できます。
成功した経験を優先的に学習に再利用する「優先度付き経験再生」や、目標報酬を逆算する「逆強化学習」も、スパース報酬環境の改善手法として広く利用されています。
まとめ

本記事では、機械学習の中でも注目度の高い強化学習について、その基本概念から主要アルゴリズム、さらに実務応用までを整理しました。
強化学習は「状態・行動・報酬」というシンプルな枠組みに基づきながらも、エピソード設計や方策の探索戦略、値関数の近似方法など、実際の実装では多くの工夫が必要です。価値ベース手法(Q-learning、DQNなど)と方策ベース手法(方策勾配、Actor-Critic系)にはそれぞれ長所と短所があり、タスクの性質や制約条件に応じて選択することが重要です。
レコメンドや広告入札、ロボティクスなどの事例からもわかるように、強化学習は単なる理論的研究にとどまらず、実務的に大きな価値を持つ技術です。安全性やスパース報酬といった現実的な課題を考慮せずに導入すると、期待する成果を得られない可能性もあります。報酬設計や探索・活用のトレードオフ、オフライン学習の活用など、ビジネスKPIとの整合性を保ちながら設計することが成功の鍵です。
今後はPPOやSACといった最新アルゴリズムや、RLHF(人間のフィードバックを用いた強化学習)などの応用が広がりつつあり、機械学習の中でも実用性の高い分野としてますます発展していくことが予想されています。
このような基礎を理解し、適切な設計パターンを学ぶことが、強化学習を活かす第一歩となります。


